사용할 만한 머신러닝 / 딥러닝 모델을 만들기 위해서 알아야 할 사전 지식들
1. 데이터 수집
크롤링, 스크래이핑
1. HTML, CSS (selector) 웹 크롤링 (urllib.request / requests - bs4)
2. selenium
3. Naver / Kakao / google 등의 RESTful API
2. 데이터 저장
RDBMS, NOSQL + ( Hadoop - HDFS )
1. MySQL, Oracle, Maria DB 등의 RDBMS
2. Redis, MongoDB 등의 NoSQL
3. 데이터 조회 및 분석( 시각화 )
Spark / Hive / Pandas / Matplotlib, seaborn 등이 포함
1. 상관 관계 조사하기
2. 인사이트 도출해 내기
4. 수학
Sum / Product?
sigma / pi
평균
크로스 앤트로피, MSE, softmax sigmoid 등
데이터 사이언스 - 수학
A new tool for teams & individuals that blends everyday work apps into one.
www.notion.so
5. numpy
6. 머신러닝
_______________________________________________________________________________________________________________
머신러닝 = 기계 학습 -> 기계는 함수라고 생각하면 됨
머신러닝 = 데이터의 패턴찾기!!
________________________________________________________________________________________________________________
지도학습, 비지도 학습, 준지도 학습, 강화 학습 개념
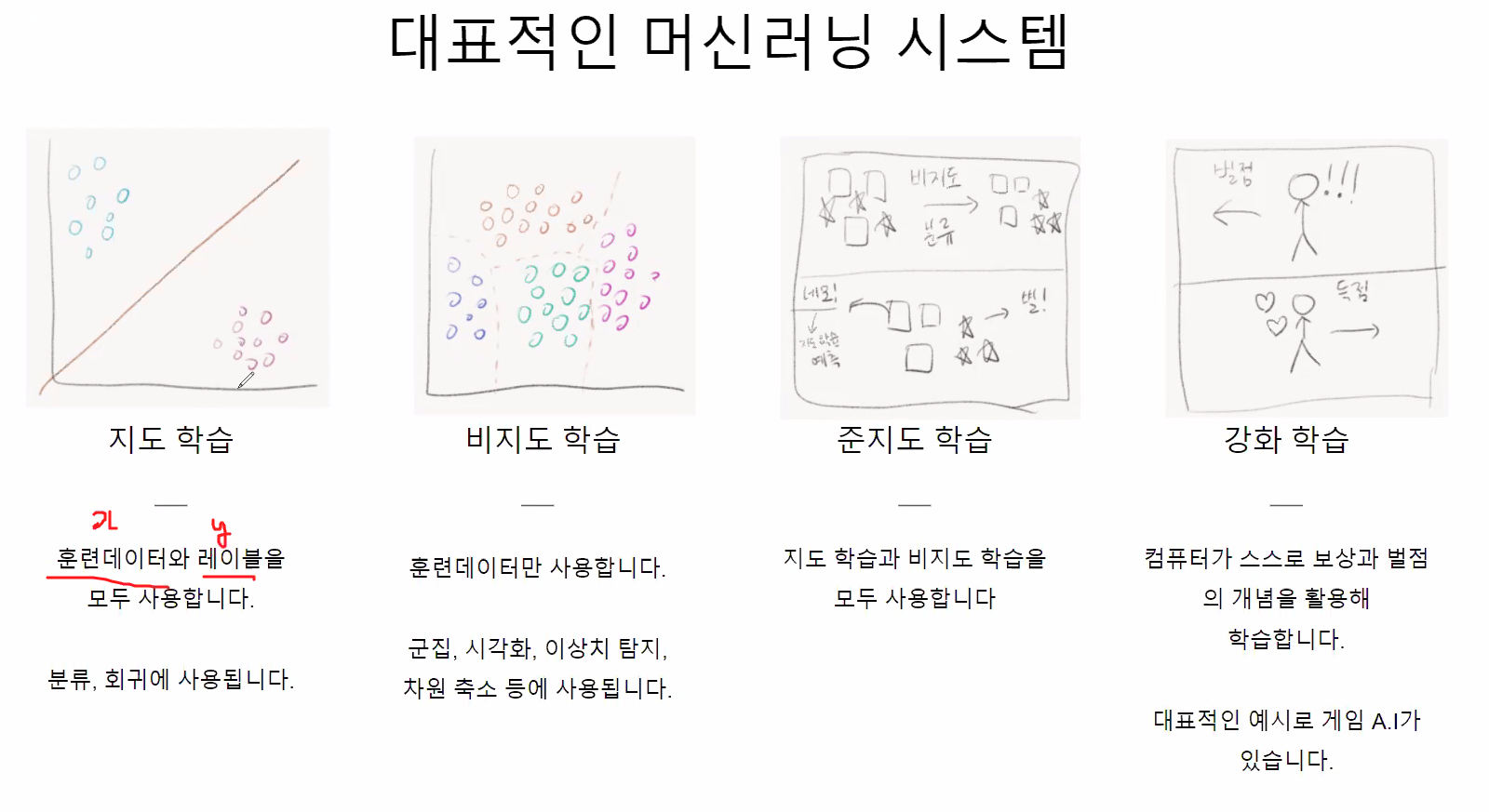

________________________________________________________________________________________________________________
데이터의 일반화
- 분석(모델링)
- 개발(모델 + web(모바일))
__________________________________________________________________________________________________________________
프로젝트 성공적으로 마무리 하기
1. 절대 특이한거 하려고 하지 말기 (기술을)
- 누구나 할 수 있는 정말 쉬운 주제로 시작하기
- 이걸 완성을 시켜 가면서 추가적으로 생각을 하는거에요
ex. 모델을 조금 더 복잡하게 만들던(논문 연구)
ex. 웹 서비스를 추가적으로 개발 하던..
2. 여러분들은 이걸로 사업을 하실게 아니에요
- 3개월 배워서 특이한 무언가를 어떻게 만듭니까..
- 대부분의 사람들이 거의 뭐 사업성을 생각해서 만드니까
- 특이한 것을 찾아야 하고 그 결과 보통 실패해요
3. 여러분들이 보여주셔야 할 것은
- 내가 이 정도 할 줄 안다....를 보여줘야 하는 것
- 회사에서는 뭘 볼까?
ex. 논문 연구 및 논문을 통한 컨텐츠 개발
ex. YOLO 논문을 읽고 주제에 맞는 Object Detection을 수행해서 무엇인가를 만드는...
- 정리하자면 논문 읽고 컨텐츠에 맞게 논문에 나와있는 개념을 사용하는 것
- 분석이 될 수도 있고, 모델링이 될 수도 있다.
논문을 보고 이 논문을 우리 프로젝트에 어떻게 적용시켜야겠다. 라는 생각을 가지는게 훨 낫습니다.
특이한거 없는거 하려고 하지 마세요 * 필요한거를 하려고 하세요
ex. 기상, 농수산물 데이터 가지고 와서 웹서비스로 뭘 만들고...
농 수산물 데이터랑 기상 데이터를 매칭을 어떻게..?
보통 데이터 수집이 어렵거나 특이한 경우가 주제가 특이함
추가 질문:

__________________________________________________________________________________________________________________

__________________________________________________________________________________________________________________